
A growing number of cities are increasingly mediated and navigated through the lens of Google Maps or the likes of Foursquare. Over the last ten years, Big Tech firms have become cartographers of data, digitally mapping how people interact in a city from continuously updated activity gleaned from our smartphones. This world is in a seemingly perpetual state of documentation through social media. Geotags – those harmless images of that new pop-up restaurant on Instagram, or that Facebook check-in at an art gallery at the weekend – have now become a ubiquitous part of everyday life in the data economy. Likewise, civic and governmental data, on everything from house prices, crime statistics, rough sleeping, alcohol consumption, personal income and unemployment are now readily available online.
It was only a matter of time before the real estate sector – an industry based on the calculation, quantification and commoditization of space – sought to capitalize on this accumulation of everyday data. A new industry is emerging within real estate comprised of large companies and smaller start-ups with the sophisticated title ‘PropTech’. A range of such ‘PropTech’ companies are now linking machine learning algorithms to data amassed on various sociological and historical factors to predict which areas in major cities look ripe for investment; a process uniting both commercial and residential real estate in an unholy communion with Big Tech companies and the store of data they’ve collected.
Take the example of WeWork, who now use various data metrics when deciding on the location of their offices. To do this, WeWork collaborate with Factual: a relatively unknown but financially colossal data company who digitally map and categorise location information from millions of online sources — a process one could describe as a global data cartography. This data mapping captures information on community and governance, local landmarks, transportation infrastructure, healthcare, business and other services in over 52 countries, eventually handing this locational intelligence to the likes of Uber, Amazon, Apple and SquareSpace.
Using this data, WeWork have created an index of amenities the neighborhood of any office must have – one which is thoroughly dense and urbane. From screenshots published by WeWork of an example case in Manhattan, this index includes broad information on the estimated amount of workers in area, the number and size of businesses, while also noting the specific collections of coffee shops, shopping, restaurants, nightlife, hotels and fitness facilities.
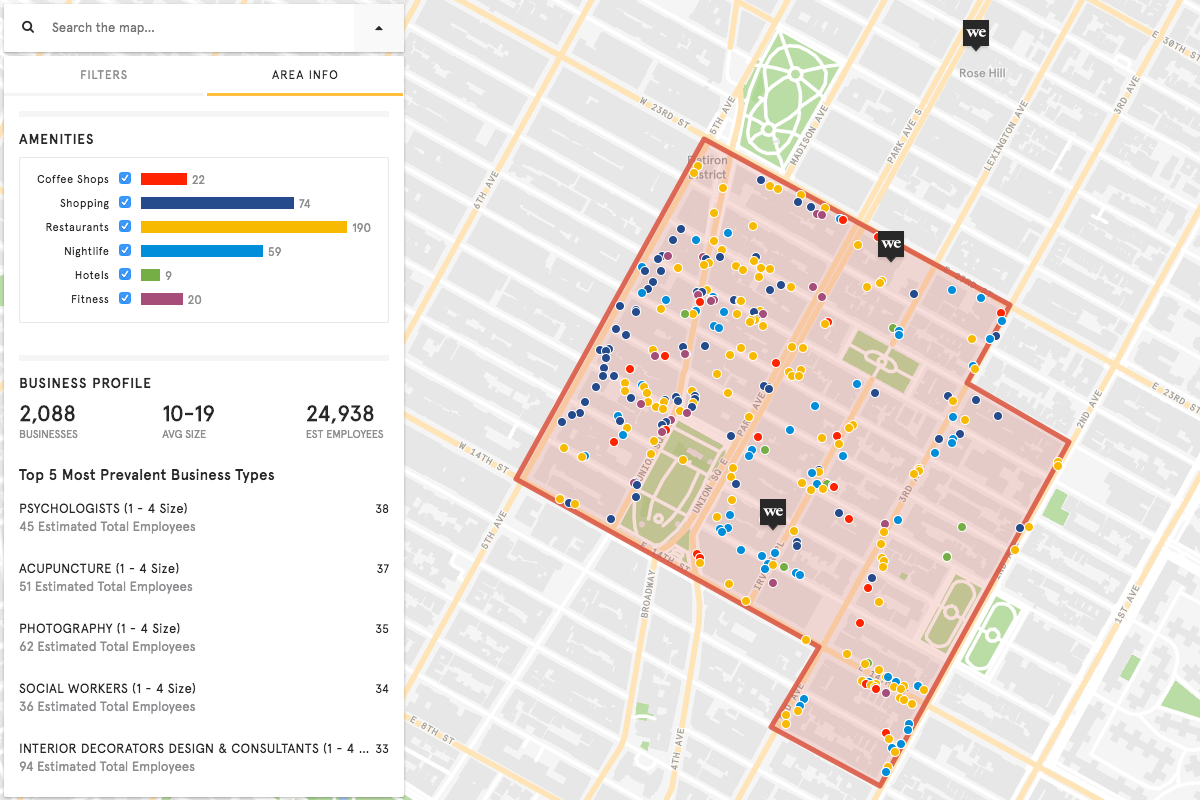
Screenshot of WeWork’s urban data mapping interface developed by Factual.
From this, WeWork can instantly assess whether the potential location of an office suits their magic formula of neighbourhood amenities, or as Factual claim “this data enabled automation of building amenity profiles to gauge the energy of particular neighborhoods with the click of a button”. The standardisation of this process has led to the aggressive expansion of WeWork globally, with 517 offices now in 96 cities. All seem to follow the same formula pertaining to a certain lifestyle: an algorithmic model of Richard Florida’s ‘creative class’ and corresponding ‘lifestyle amenities’.
Yet the use of algorithms to govern real estate investment doesn’t stop with offices. Using a similar approach to WeWork but in the residential sector, Skyline AI – an “artificial intelligence asset manager for commercial real estate” – have set themselves the task of introducing the world of property investment to high-frequency trading. In Skyline’s own words, they want property investment to become less intuitive and more data-driven and scientific, so that it’s “more comparable with what we’re used to from the stock market, where robotic trading is currently responsible for about 70-80% of trading”. To do this, Skyline AI identify apartment blocks with a minimum of 50 flats that are ‘inefficient’ in the rental market in relation to their total cost, before teaming up with the largest property investment companies to make an offer. In a similar setup to WeWork, Skyline AI use a Google Maps-based application to create an algorithmic ‘representation’ of a property in relation to its urban environment, including physical distances to ‘points of interest’ such as schools, parks, restaurants and general infrastructure.

Screenshot of Skyline AI’s proprietary interface, taken from co-founder Or Hiltch’s presentation at Calcalist’s 2018 Mind the Data conference in Tel Aviv.
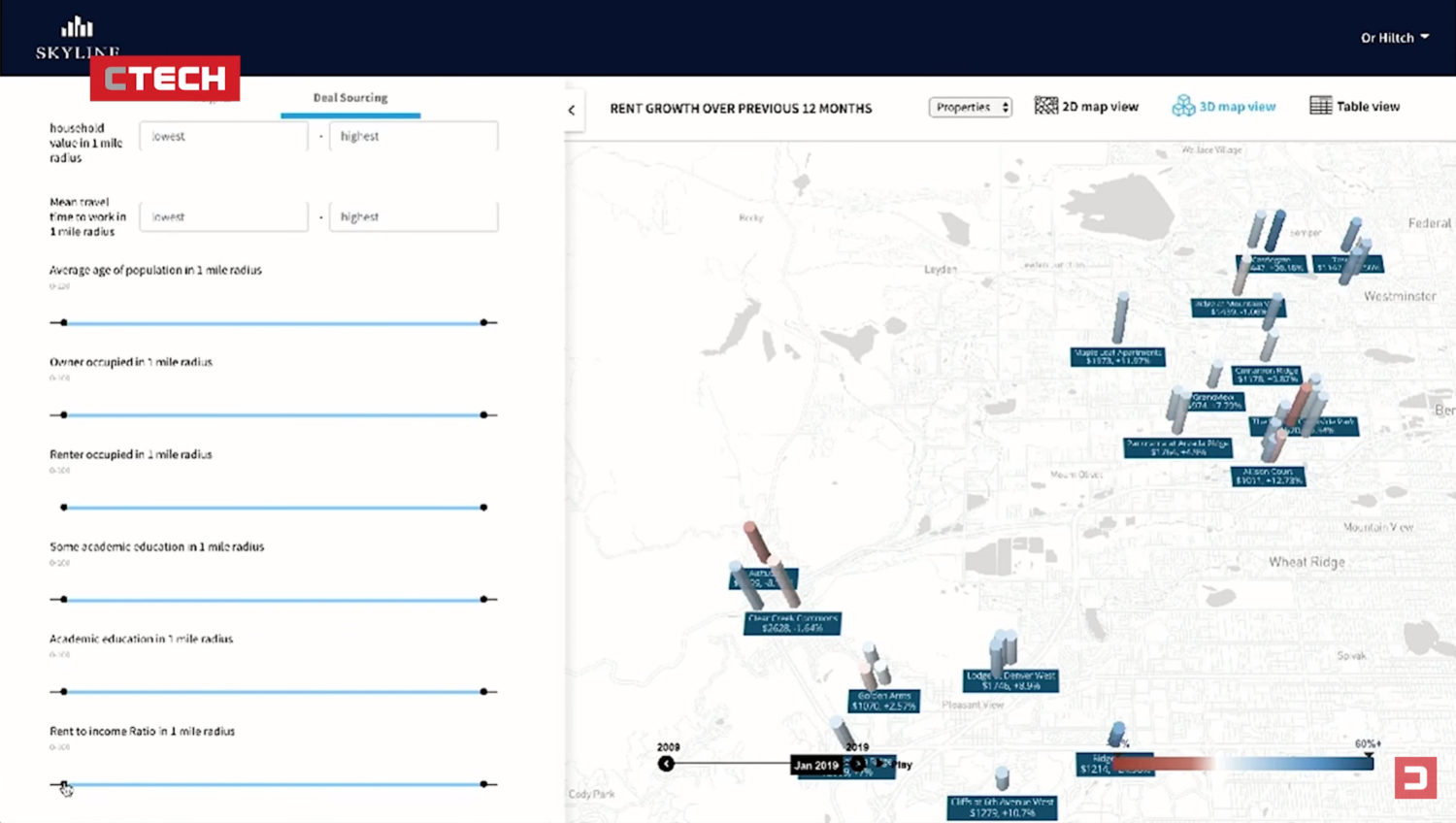
Screenshot of the Skyline AI interface from same presentation, with demographic parameters applied.
Current vectors of more prosaic ‘amenities’ are further referenced with data going back 50 years on crime, demographics, LIBOR rates and the stock market, while also including financial information on the property itself such as debts and transactions. This information is visualised through a proprietary digital interface, with which over 400,000 properties in the US are mapped using 10,000 individual bits of data per property and interactively explored, much like a simulation game, through parameters such as rent to income ratio, rent to occupancy or valuation above $50 million. The results give a 15-year prediction for each property instantly showing the cash flow projection with a corresponding ‘go, no go’ decision on whether to invest. Using this automated technology, Skyline AI claimed six months ago that the first ever ‘AI-driven’ residential property acquisition took place: two apartment blocks in Philadelphia brought for $26 million which they claim were mismanaged and not generating the profit they could be.
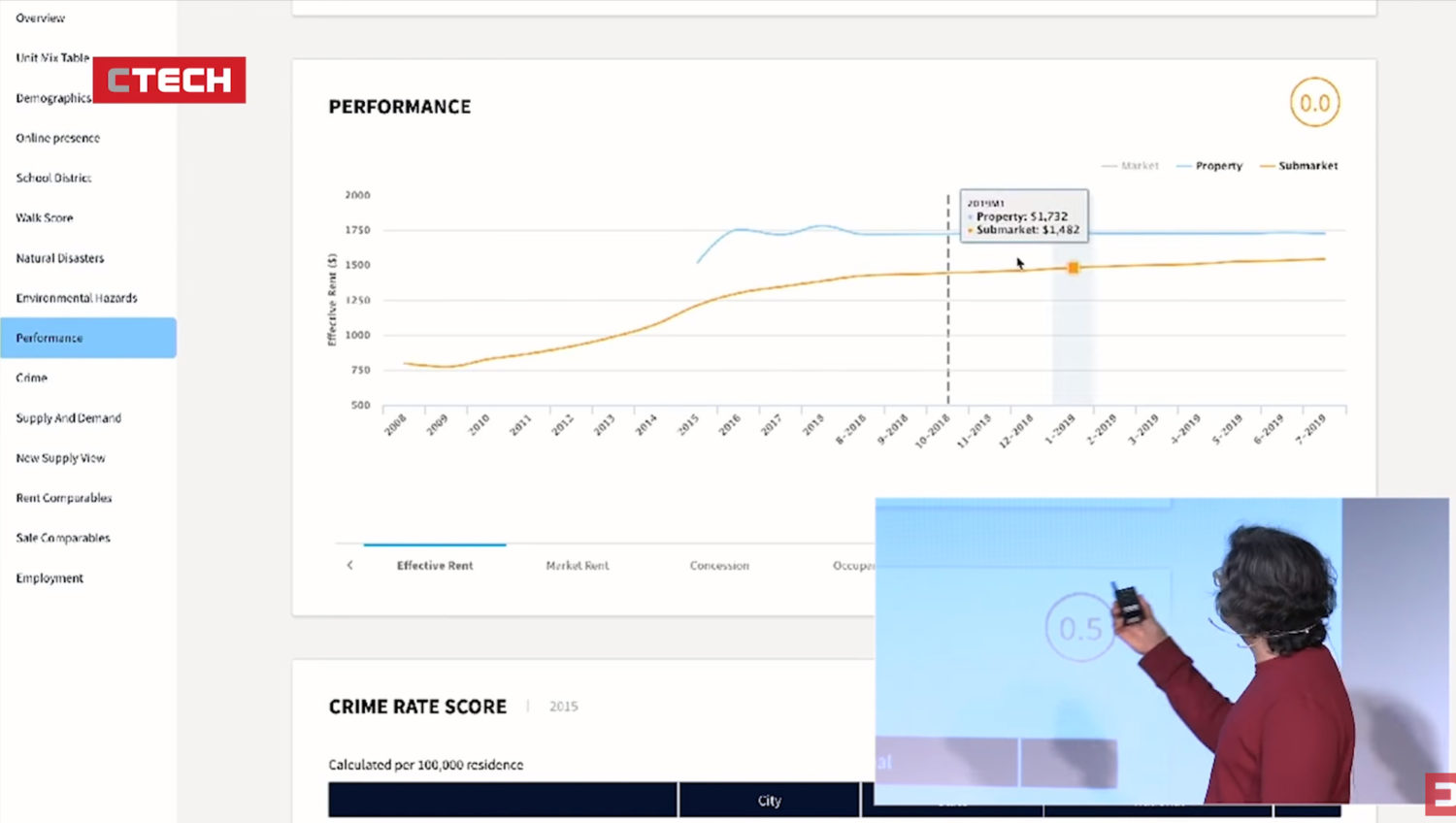
Screenshot of Skyline AI co-founder Or Hiltch explaining analytical capabilities of the software at the 2018 Mind the Data conference in Tel Aviv.
Also working in the residential sector, but operating at the scale of individual homes, is the startup Proportunity who aim to “make buying a home more affordable” by “applying A.I. technologies to understand the potential of tomorrow, enabling us to help people buy a home today”. Proportunity targets “people on middle incomes” where “affordable housing is becoming scarce” by predicting, through machine learning, which postcodes are on the cusp of gentrification in London. Once they have found a home to purchase, they offer a loan set against the properties likely to increase in value as an area develops. To quantify gentrification, Proportunity aggregates data such as levels of unemployment, crime rates, school ratings and transport links. Consumption habits, measured by social-media check-ins or whether certain retailers like Whole Foods have plans to move into an area, are also used to detect the changing social character of an area. More bizarrely, it also uses governmental statistics related to chemical compounds found in sewers to calculate what drugs are popular in an area. They claim a decrease in crack cocaine found in local sewers is an indicator of a changing social mix.
On top of an analysis of a neighbourhood, Proportunity claim they have also taught an algorithm to predict gentrification using historical data covering gentrified suburbs in London to determine what social factors correlate with changes in property prices. Featured in London’s The Evening Standard ‘Home and Property’ section – a newspaper very much a torch bearer for the continued commodification of housing – Proportunity claim their algorithm had identified Barking and Dagenham, one of the poorest wards, as a borough to invest in, with flats prices rising by 30%.
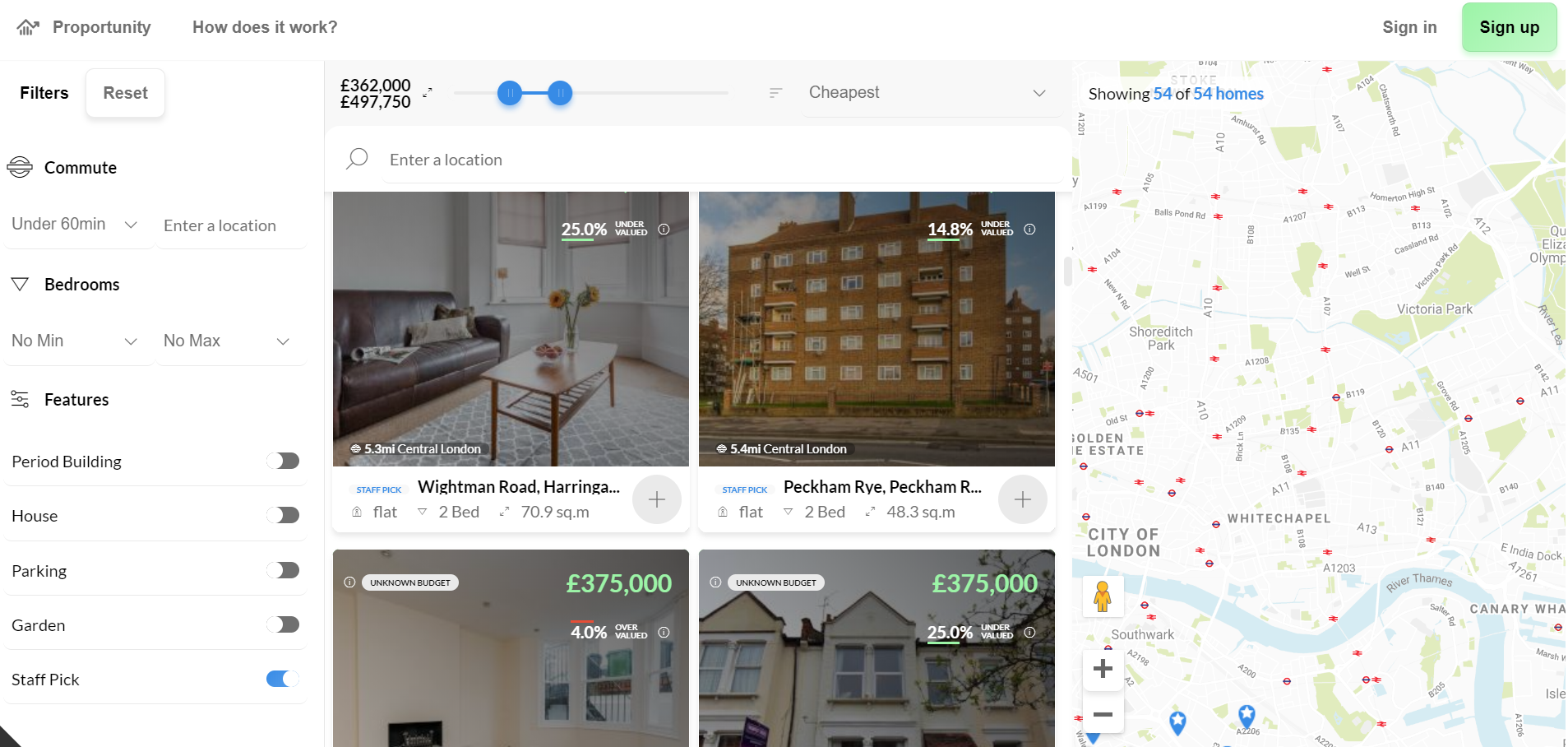
Screenshot of Proportunity’s “smart platform.”
What might be the implications of these developments? Culturally, a contradictory situation may arise where architects and urban designers, who today might be working with the best of intentions under rubrics of localism, cannot escape wider shifts towards a global, all-devouring data economy. This is particularly true for any urban approach that holds forms of consumption or cultural capital at its core, no matter how local, ethical, or sustainable. Ultimately, an approach that appears authentic and favours craft, bottom-up tactics — the small, local and everyday — can be quantified through social media and mapping applications to create an algorithmic representation of an area. And if this representation can be used to instantly gauge whether a neighbourhood is worth investing in, new tactics beyond localised consumption may need to be formed to further resist gentrification.
More tellingly, and leaving aside the wider role of automation at work, we could place these developments firmly within a momentum that persists between urbanization and financialization; one mitigated by real estate markets and effectively unaltered post-2008 and the subprime mortgage crisis. To describe this process more bluntly, capital is continually looking for new opportunities within the built environment to invest in, be it the funding of new developments or the acquisition of existing assets, thus bringing physical space into the liquid world of financial markets. Working in this latter process, WeWork and Skyline AI have the backing of dominant global investment funds, including SoftBank Group and Deutsche Bank, while all three team up with large mortgage lenders to underwrite any loans.
Through developments in real estate algorithms, what emerges is a more systemic, calculable and accelerated model concerning the extraction of value from physical space that has taken place over the last thirty years. It is one which claims to be objective and driven by economic rationality, yet it is steeped in the language of the AI occult: a danger being the hysteria surrounding automation taking on its own mad dance, whether it works or not. An algorithm may suggest an otherwise bizarre direction for investment, unbeknownst to a person, based on crunching thousands of bits of data. But the final decision to invest still rests firmly on human input. Seduced by the hype, speed and potential profits from real estate algorithms, it’s human input that will send this process tailing off into unfixed directions. What is clear, however, is that data collected by Big Tech platforms can now be exploited by property investors, in another example of the ever-increasing overlap of digital and physical space. And the data created through our tags, check-ins and posts are now potentially the logs to fuel an accelerated fire of urban restructuring.